近日,Character.AI公司在X平臺上發布了一項令人矚目的新技術——AvatarFX模型,該模型能夠將靜態圖片中的人物賦予生命,讓他們“開口說話”。這一創新技術引發了廣泛關注和討論。
用戶只需上傳一張圖片,并從平臺提供的聲音庫中選擇一個聲音,AvatarFX模型就能迅速生成一個會說話、會移動的形象。這些形象不僅動作自然流暢,還能準確地表達情感,真實感令人驚嘆。這一技術的實現,得益于Character.AI公司研發的一種名為“SOTA DiT-based diffusion video generation model”的先進AI模型。
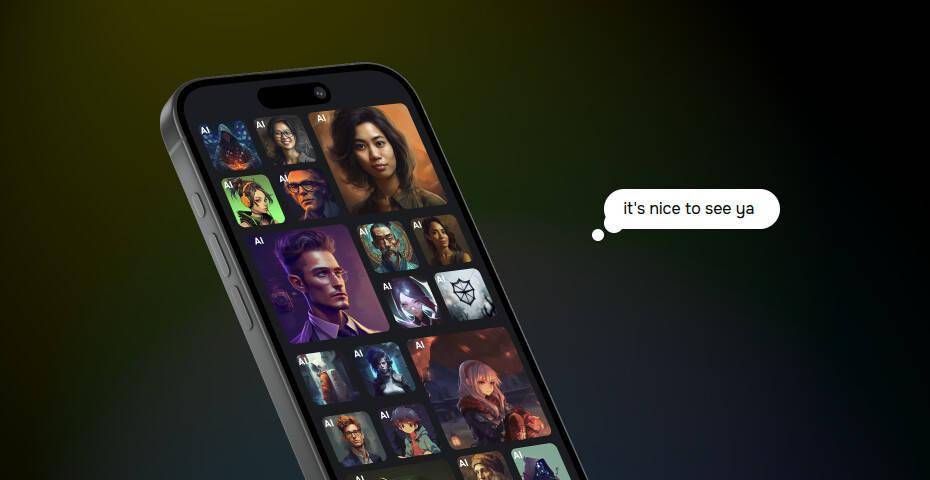
據了解,該模型經過長時間的訓練和優化,結合了音頻條件優化技術,能夠高效地生成高質量的視頻內容。為了展示這一技術的實際效果,Character.AI公司還附上了一段演示視頻。

AvatarFX模型的技術亮點在于其出色的“高保真、時間一致性”視頻生成能力。即使面對復雜的場景,如多角色、長序列或多輪對話,AvatarFX模型也能保持驚人的速度和穩定性,生成的視頻內容質量極高。與目前市場上的一些競爭對手,如OpenAI的Sora和Google的Veo相比,AvatarFX模型并非從零開始或基于文本生成視頻,而是專注于將特定的靜態圖片動畫化,為用戶提供了全新的使用體驗。
然而,這一技術的出現也引發了一些潛在的風險和爭議。由于AvatarFX模型能夠生成高度逼真的虛假視頻,用戶可能會上傳名人或熟人的照片,制作看似真實的對話視頻,從而引發隱私和倫理問題。因此,Character.AI公司在推廣這一技術的同時,也強調了用戶應遵守法律法規,尊重他人的隱私和權益。