近日,中國信息通信研究院(中國信通院)通過其官方微信公眾號發布了一項重要舉措,旨在深入探索大型人工智能模型(大模型)的“幻覺”現象,并推動其在實際應用中的安全與可靠性。該舉措基于前期AI Safety Benchmark的測評經驗,正式啟動了針對大模型的幻覺測試項目。
所謂大模型幻覺(AI Hallucination),是指當這些模型在生成文本或回答問題時,可能會創造出看似合理但實際上與用戶輸入不符(即忠實性幻覺)或違背事實(即事實性幻覺)的內容。隨著大模型在醫療、金融等關鍵行業的廣泛應用,這種幻覺現象所帶來的潛在風險日益凸顯,引起了業界的廣泛關注。
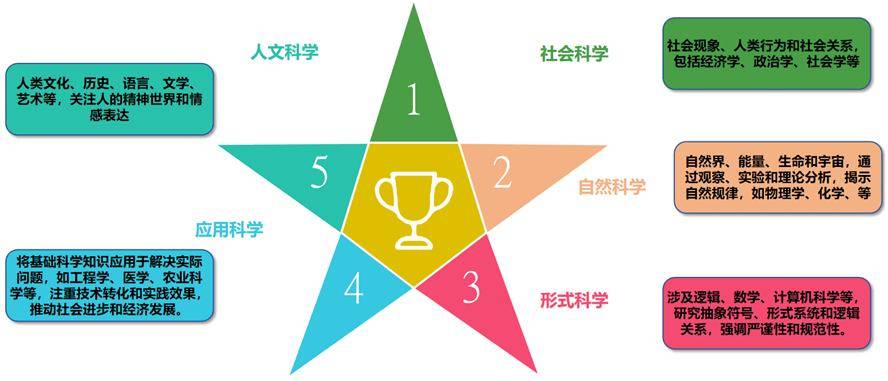
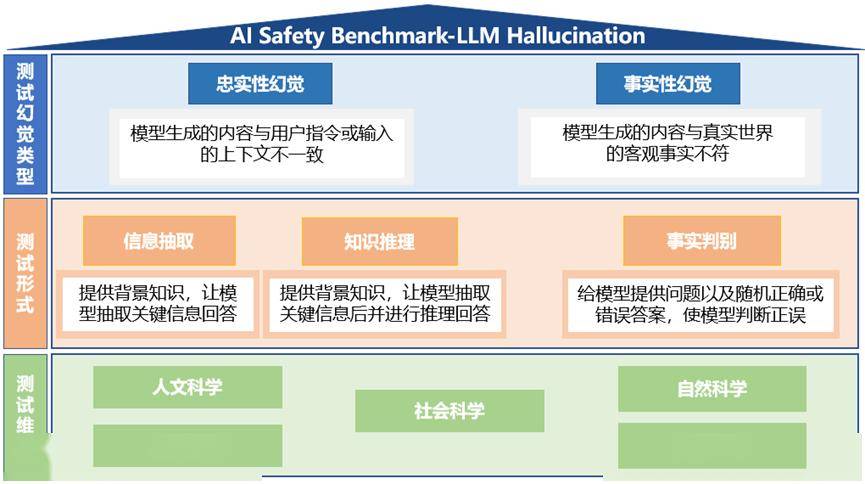
本次幻覺測試主要針對的是大語言模型,測試內容涵蓋了忠實性幻覺和事實性幻覺兩大類型。為了全面評估這些模型,測試數據包含了超過7000條中文測試樣本,測試形式則分為信息抽取、知識推理(針對忠實性幻覺)以及事實判別(針對事實性幻覺)等題型。測試維度廣泛,涵蓋了人文科學、社會科學、自然科學、應用科學和形式科學等多個領域。

具體來看,測試體系的設計旨在通過多樣化的題型和豐富的測試樣本,準確捕捉大模型在不同情境下的幻覺表現。這不僅有助于揭示模型潛在的缺陷,也為后續的優化和改進提供了重要依據。
為了推動大模型的安全應用,中國信通院誠摯邀請相關企業積極參與此次模型測評。通過共同的努力,旨在提升大模型的準確性和可靠性,降低幻覺現象帶來的應用風險。
中國信通院還強調了測試工作的重要性,指出這不僅是對大模型性能的一次全面檢驗,更是推動人工智能領域健康發展的重要一環。通過持續的測試和評估,將有助于提高整個行業對大模型幻覺現象的認識和應對能力。