近期,Hugging Face攜手英偉達(dá)及約翰霍普金斯大學(xué)的研究人員,共同推出了BERT模型的全新升級(jí)版本——ModernBERT。這一新版本不僅在效率上有所提升,更突破了原有模型在處理長(zhǎng)文本上的限制,能夠支持高達(dá)8192個(gè)Token的上下文處理。
自2018年問(wèn)世以來(lái),BERT模型一直是自然語(yǔ)言處理領(lǐng)域的熱門之選,其在Hugging Face平臺(tái)上的下載量?jī)H次于RoBERTa,每月下載量超過(guò)6800萬(wàn)次。然而,隨著技術(shù)的不斷進(jìn)步,原版BERT模型在某些方面已略顯陳舊。
面對(duì)這一挑戰(zhàn),Hugging Face及其合作伙伴借鑒了近年來(lái)LLM領(lǐng)域的最新進(jìn)展,對(duì)BERT的模型架構(gòu)和訓(xùn)練過(guò)程進(jìn)行了全面優(yōu)化,最終推出了ModernBERT。這一新版本旨在接替原版BERT,成為自然語(yǔ)言處理領(lǐng)域的新標(biāo)桿。
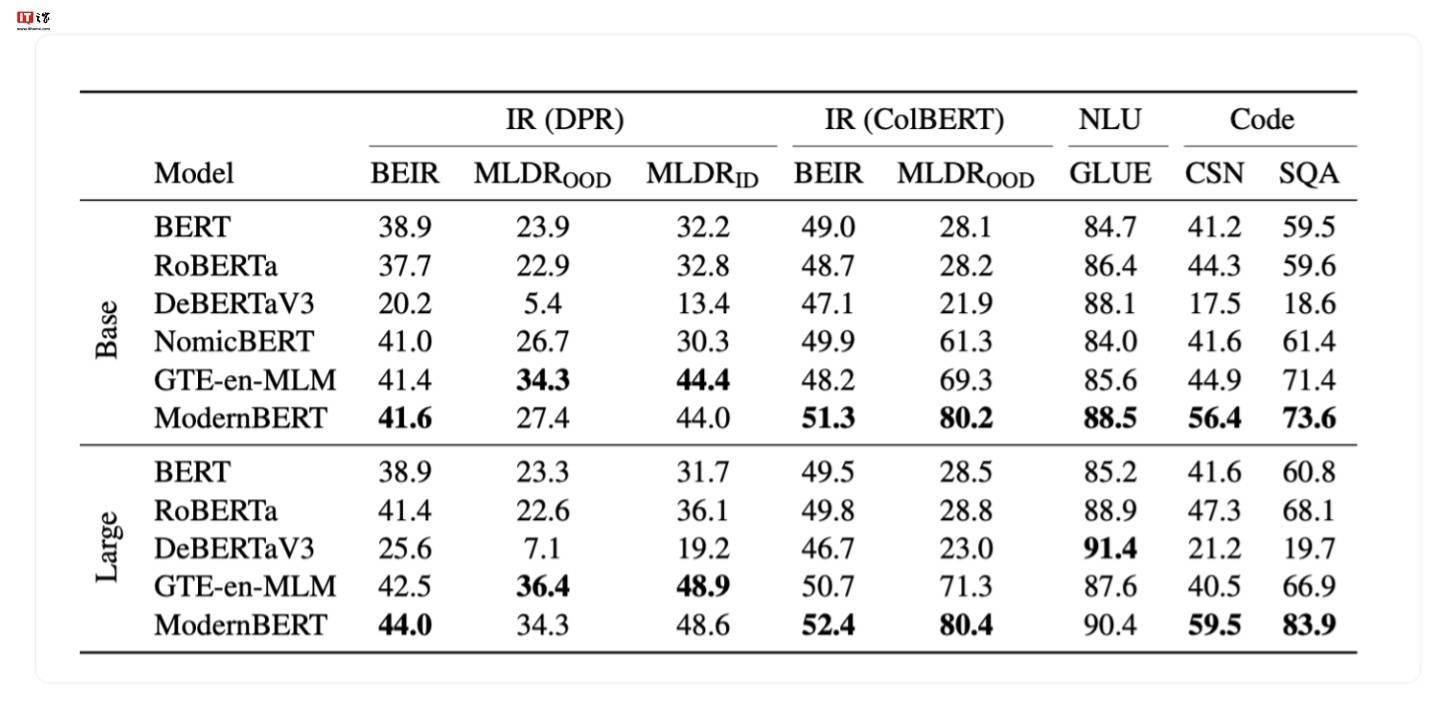
ModernBERT在基準(zhǔn)測(cè)試中的表現(xiàn)令人矚目。開(kāi)發(fā)團(tuán)隊(duì)使用了多達(dá)2萬(wàn)億個(gè)Token的數(shù)據(jù)進(jìn)行訓(xùn)練,使得該模型在多種分類測(cè)試和向量檢索測(cè)試中均取得了業(yè)界領(lǐng)先的成績(jī)。這一成果不僅驗(yàn)證了ModernBERT的先進(jìn)性,也展示了開(kāi)發(fā)團(tuán)隊(duì)在模型優(yōu)化方面的深厚實(shí)力。
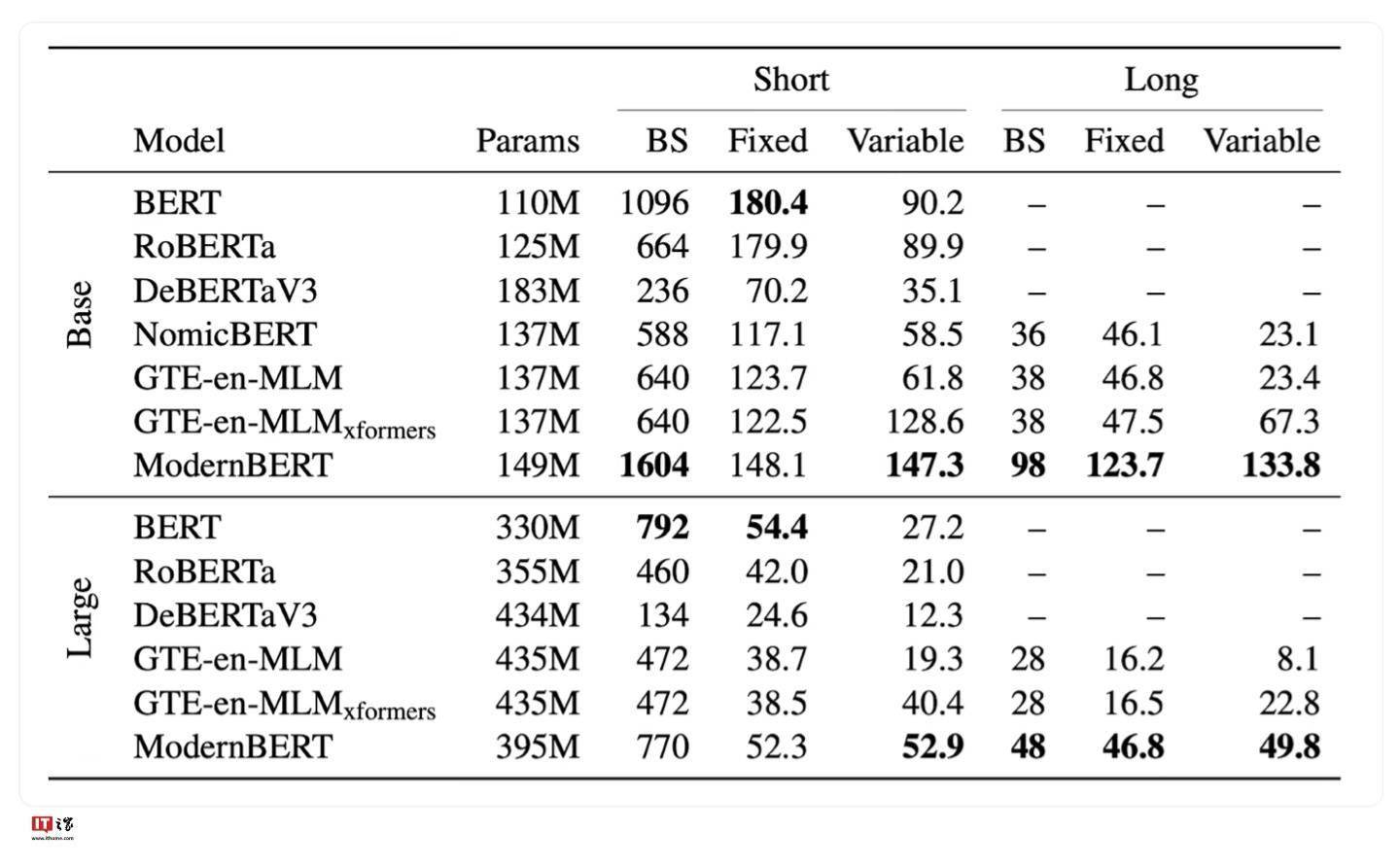
為了滿足不同用戶的需求,開(kāi)發(fā)團(tuán)隊(duì)還推出了兩個(gè)版本的ModernBERT模型,分別是擁有1.39億參數(shù)的精簡(jiǎn)版和擁有3.95億參數(shù)的完整版。這兩個(gè)版本均提供了強(qiáng)大的自然語(yǔ)言處理能力,用戶可以根據(jù)自己的實(shí)際需求進(jìn)行選擇。
目前,ModernBERT的模型文件已經(jīng)公開(kāi)發(fā)布,用戶可以通過(guò)指定的項(xiàng)目地址進(jìn)行下載和使用。這一新版本的推出,無(wú)疑將為自然語(yǔ)言處理領(lǐng)域的發(fā)展注入新的活力。





















