近期����,關于OpenAI最新推出的視頻生成AI模型Sora的訓練數據問題�,引發了廣泛的關注與討論。據多方信息顯示����,Sora可能使用了未經授權的游戲直播和視頻攻略作為訓練素材�����,這一發現迅速引起了版權和法律領域的擔憂���。
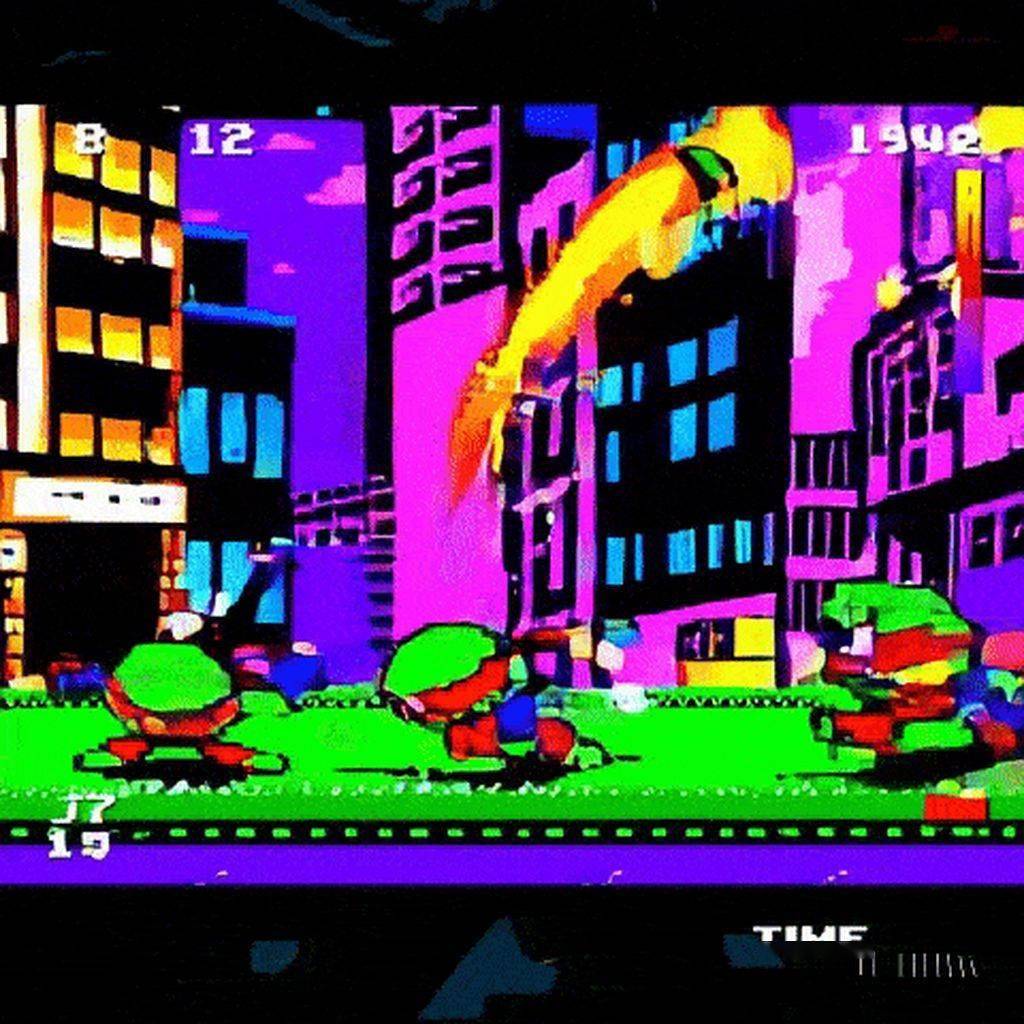
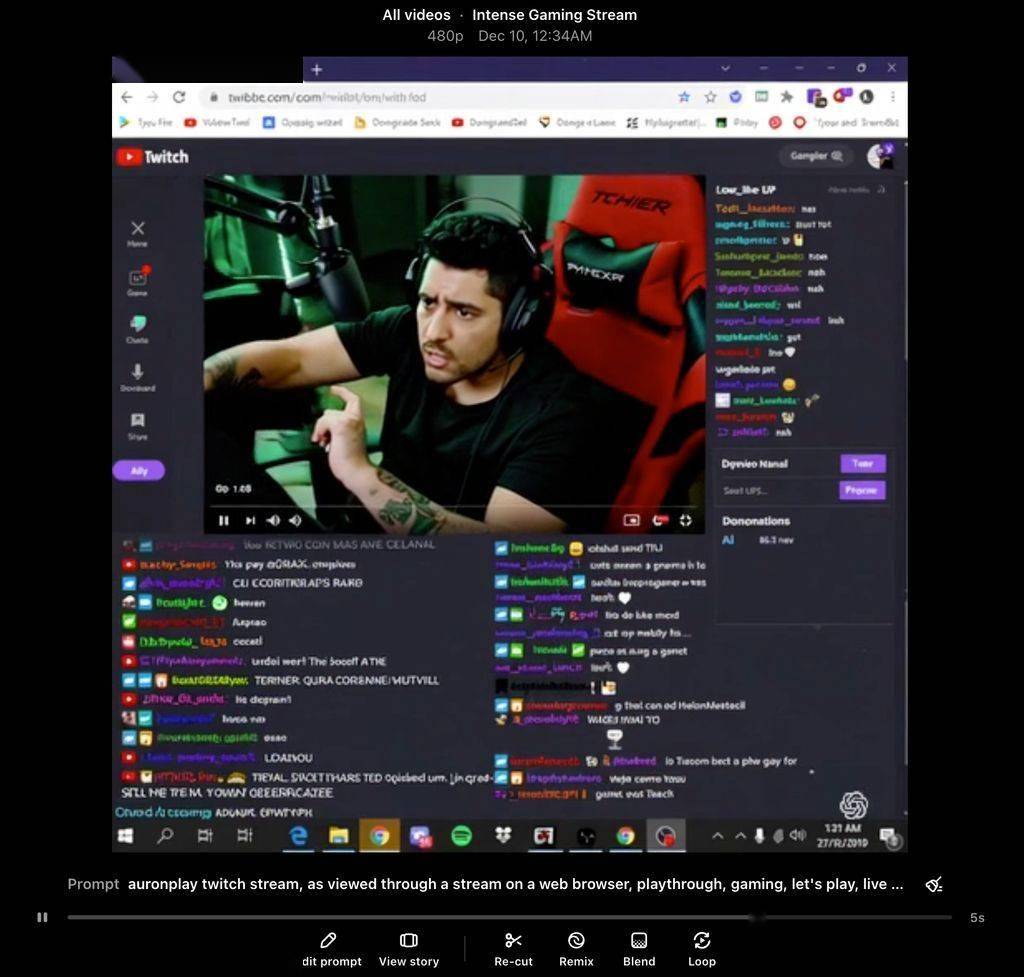
科技媒體TechCrunch在一篇報道中指出�����,Sora在開放測試后�����,用戶發現其生成的視頻中包含了多款知名游戲的畫面�����,如《超級馬里奧兄弟》、《使命召喚》���、《反恐精英》及《忍者神龜》等。更令人驚訝的是�����,一些知名的Twitch主播����,如Auronplay和Pokimane的肖像也出現在了生成的視頻中。

這一發現立即引發了版權問題的討論��。法律專家表示���,如果OpenAI確實未經授權使用了這些游戲錄像進行模型訓練�,那么將可能面臨嚴重的版權侵權風險。游戲錄像不僅包含游戲開發者所擁有的游戲內容版權,還涉及到錄像制作者的版權�����,有時還可能包括用戶生成內容的版權��,情況十分復雜。
隨著技術的發展��,人工智能在各個領域的應用越來越廣泛�����,但隨之而來的版權問題也日益凸顯�����。如何在利用人工智能技術的同時,保護原創者的合法權益�,成為了一個亟待解決的問題����。

同時���,企業也應該加強自律��,尊重原創者的知識產權��,避免使用未經授權的數據進行模型訓練。只有這樣,才能推動人工智能技術的可持續發展��,為人類社會帶來更多的福祉����。