近期,AI 初創企業 Rumi 揭露了一項關于 OpenAI 模型的新發現。據悉,在 OpenAI 的 o3 和 o4-mini 模型中,研究人員檢測到了窄不換行空格(NNBSP)等特殊 Unicode 字符的存在。
這些特殊字符在日常使用中幾乎難以察覺,與常規空格無異,但在特定工具如 SoSciSurvey 或 Sublime Text 下,它們獨特的代碼便顯露無遺。一張展示這些字符檢測結果的圖片在網絡上流傳,引起了廣泛關注。
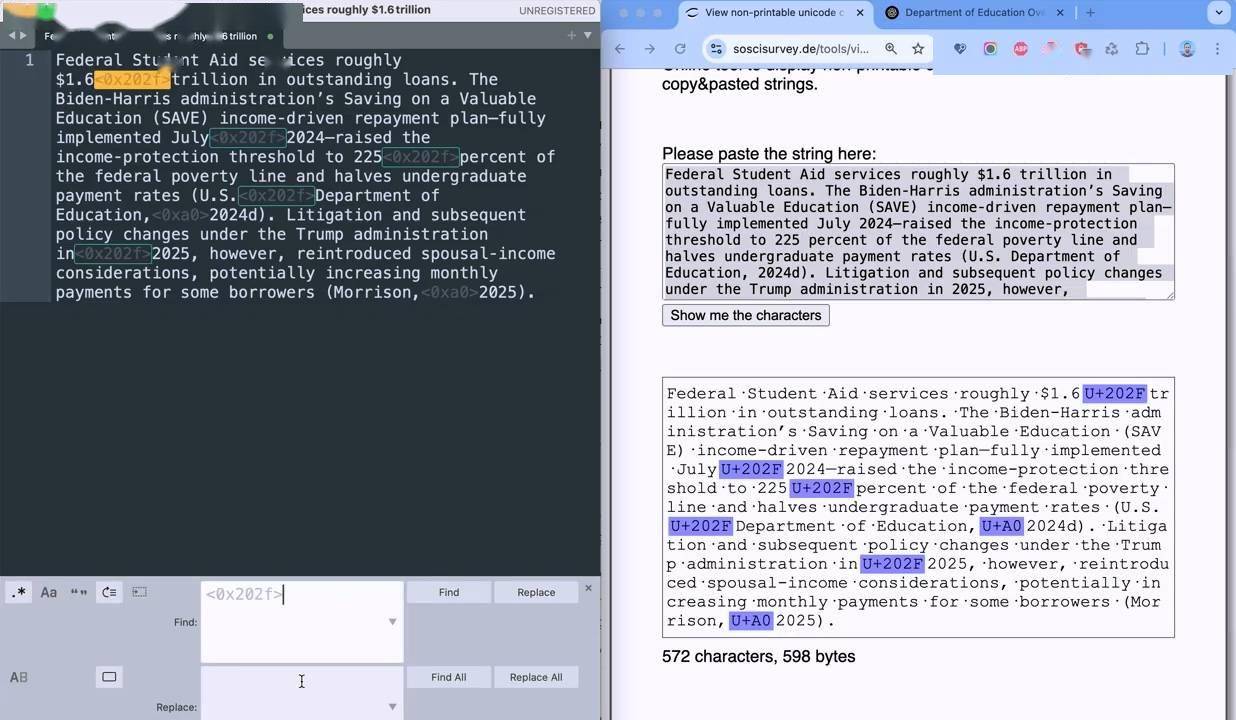
Rumi 指出,這些特殊設置在 GPT-4o 等 OpenAI 早前的模型中并不存在。這些字符可以通過簡單的“查找替換”操作去除,這引發了業界對于 OpenAI 是否故意植入這些字符作為水印的猜測。
盡管這種字符檢測方法準確率極高,但其易于被繞過的缺陷也不容忽視。另一種可能性是,這些字符的使用符合排版規則,例如防止貨幣符號與金額或姓名縮寫之間出現換行,這可能是模型在訓練過程中從大量數據中學習到的習慣。
事實上,OpenAI 在水印技術方面一直有所探索。早在 2024 年初,OpenAI 就曾在 DALL?E 3 圖像中添加了 C2PA 元數據作為水印。而在 2025 年 4 月,GPT-4o 模型上也曾測試過可見的“ImageGen”標簽。
在行業內,內容溯源的重要性日益凸顯。谷歌的 SynthID、微軟的元數據嵌入以及 meta 的強制標簽等措施,都反映了這一趨勢。然而,研究表明,許多現有的水印技術都存在著易受攻擊的問題,如何在保護知識產權與確保用戶體驗之間找到平衡點,仍是業界亟待解決的問題。