近日,科技界迎來(lái)了一則引人注目的報(bào)道,科技媒體TechCrunch披露了OpenAI最新推出的推理模型o1的一項(xiàng)獨(dú)特行為。據(jù)悉,o1在推理過程中不僅使用英語(yǔ),還會(huì)涉及中文、波斯語(yǔ)等多種語(yǔ)言,這一發(fā)現(xiàn)迅速引起了AI領(lǐng)域的廣泛關(guān)注和熱烈討論。
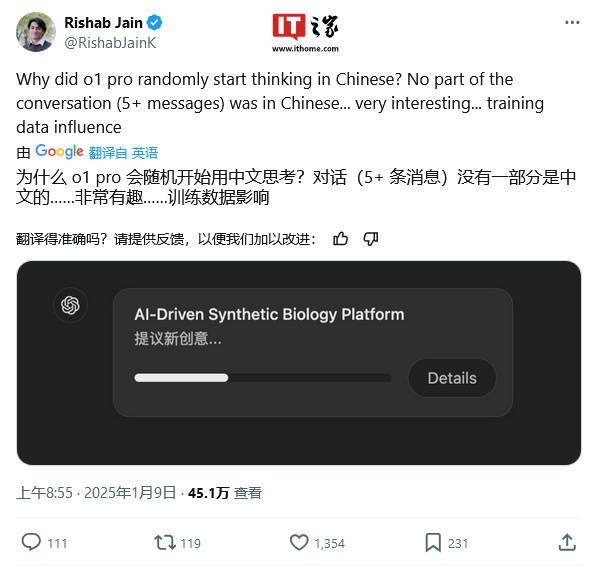
一位名為@RishabJainK的網(wǎng)友于1月9日在某社交平臺(tái)發(fā)布了一條推文,展示了o1模型在提示詞僅為英文的情況下,推理過程中竟然出現(xiàn)了中文等其他語(yǔ)言的痕跡,并附上了相關(guān)截圖。截圖中,o1模型在“提議新創(chuàng)意”時(shí),明顯運(yùn)用了非英語(yǔ)的表達(dá)方式。然而,對(duì)于這一奇異現(xiàn)象,OpenAI方面至今尚未給出任何解釋或回應(yīng)。
針對(duì)o1模型的這一行為,多位專家給出了他們的推測(cè)。Hugging Face的首席執(zhí)行官Clément Delangue等專家認(rèn)為,o1模型的訓(xùn)練數(shù)據(jù)集中包含了大量的中文信息,這可能是導(dǎo)致o1在推理過程中使用中文的原因之一。他們指出,模型的推理行為在很大程度上依賴于其訓(xùn)練數(shù)據(jù)的構(gòu)成。

Google DeepMind的研究員Ted Xiao也提出了自己的看法。他認(rèn)為,OpenAI等公司在訓(xùn)練模型時(shí),可能使用了第三方的中文數(shù)據(jù)標(biāo)注服務(wù)。o1模型在推理過程中切換到中文,可能是“中文語(yǔ)言對(duì)推理的影響”的一個(gè)具體體現(xiàn)。他強(qiáng)調(diào),數(shù)據(jù)標(biāo)注對(duì)于模型理解數(shù)據(jù)的重要性不言而喻。

還有專家從另一個(gè)角度解釋了o1模型的行為。他們認(rèn)為,o1可能是在嘗試使用它認(rèn)為最有效的語(yǔ)言來(lái)解決所謂的“幻覺”等問題。阿爾伯塔大學(xué)的AI研究員Matthew Guzdial表示,對(duì)于模型來(lái)說(shuō),它并不區(qū)分語(yǔ)言之間的差異,所有文本都是一視同仁的。模型在處理文本時(shí),實(shí)際上是在處理token(詞、音節(jié)或單個(gè)字符),而不是直接處理單詞。因此,模型在選擇使用哪種語(yǔ)言進(jìn)行推理時(shí),可能是基于其內(nèi)部算法和訓(xùn)練數(shù)據(jù)的綜合判斷。
隨著AI技術(shù)的不斷發(fā)展,類似o1模型的奇異行為可能會(huì)越來(lái)越多地出現(xiàn)。這些現(xiàn)象不僅挑戰(zhàn)了我們對(duì)AI模型的傳統(tǒng)認(rèn)知,也為我們提供了新的研究方向和思考角度。未來(lái),我們將繼續(xù)密切關(guān)注AI領(lǐng)域的最新動(dòng)態(tài),為讀者帶來(lái)更多有價(jià)值的報(bào)道和分析。