阿里云近期在人工智能技術領域邁出了重要一步,隆重推出了其新一代多模態(tài)旗艦模型Qwen2.5-Omni,這款模型的問世標志著在全方位多模態(tài)感知能力上的重大突破。
Qwen2.5-Omni的亮點在于其能夠無縫處理文本、圖像、音頻以及視頻等多種輸入形式,并以一種即時且流暢的流式響應方式,生成相應的文本和自然語音合成輸出。這一特性使其在多種應用場景中展現(xiàn)出極高的靈活性和實用性。

據(jù)阿里云官方透露,Qwen2.5-Omni采用了前沿的Thinker-Talker雙核架構(gòu)設計。具體而言,Thinker模塊如同智慧的大腦,負責深度解析和處理來自文本、音頻、視頻等多種模態(tài)的輸入信息,生成高層次的語義表征和對應的文本內(nèi)容。而Talker模塊則扮演了發(fā)聲器官的角色,它接收Thinker模塊傳遞的實時語義表征和文本,通過流式處理技術,高效地將這些信息轉(zhuǎn)化為連貫、自然的語音輸出。
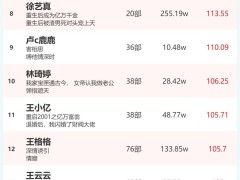
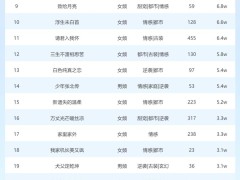
在嚴格的測試中,Qwen2.5-Omni展現(xiàn)了其卓越的多模態(tài)處理能力。與規(guī)模相近的單模態(tài)模型以及封閉源模型相比,如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro,Qwen2.5-Omni在圖像、音頻、音視頻等多個模態(tài)場景下的表現(xiàn)均更為出色。這一成績不僅驗證了其在技術上的先進性,也為其在實際應用中的廣泛推廣奠定了堅實的基礎。