靈初智能在近期正式揭曉了其最新研發成果——基于強化學習(RL)技術的端到端具身模型Psi R0。這款模型在雙靈巧手的協同操作上實現了突破,能夠串聯并混合訓練多種技能,生成具備邏輯推理能力的智能體,從而成功完成一系列復雜的、長距離的靈巧操作任務。
Psi R0不僅具備出色的操作技能,還展現出了跨物品和跨場景的泛化能力。在電商場景中,商品打包是一個典型的長流程任務,需要對成千上萬件商品進行抓取、掃碼、放置以及塑料袋打結等一系列操作。令人驚嘆的是,Psi R0憑借其雙靈巧手,能夠流暢地完成這一系列繁瑣的步驟,據官方介紹,這一表現足以替代一個完整的工作崗位。

靈初智能透露,Psi R0模型利用了海量的仿真數據進行訓練,通過雙向訓練框架將多種技能串聯起來,率先在開放環境中完成了長程任務。該模型展現出了強大的泛化能力和魯棒性,能夠在不同的環境和條件下穩定工作。
為了實現這一目標,靈初智能開發了一種獨特的技能訓練框架。該框架從物體的時空軌跡中提取關鍵信息,構建出通用的目標函數,從而解決了獎勵函數設計困難的問題。在后訓練階段,通過引入少量的高質量真實機器數據,進一步提升了長程任務的成功率。

雙向訓練框架中的轉移可行性函數在技能串聯過程中起到了至關重要的作用。該函數能夠微調技能,提高串聯的成功率和泛化性,同時賦予模型自主切換技能的能力。當遇到操作失敗時,Psi R0能夠迅速調整策略,確保任務的高成功率。
這一創新不僅展示了靈初智能在強化學習領域的技術實力,也為機器人技術的發展開辟了新的方向。Psi R0的成功應用,預示著未來機器人在長程靈巧操作任務中將發揮更加重要的作用,為工業自動化和智能化進程注入新的動力。
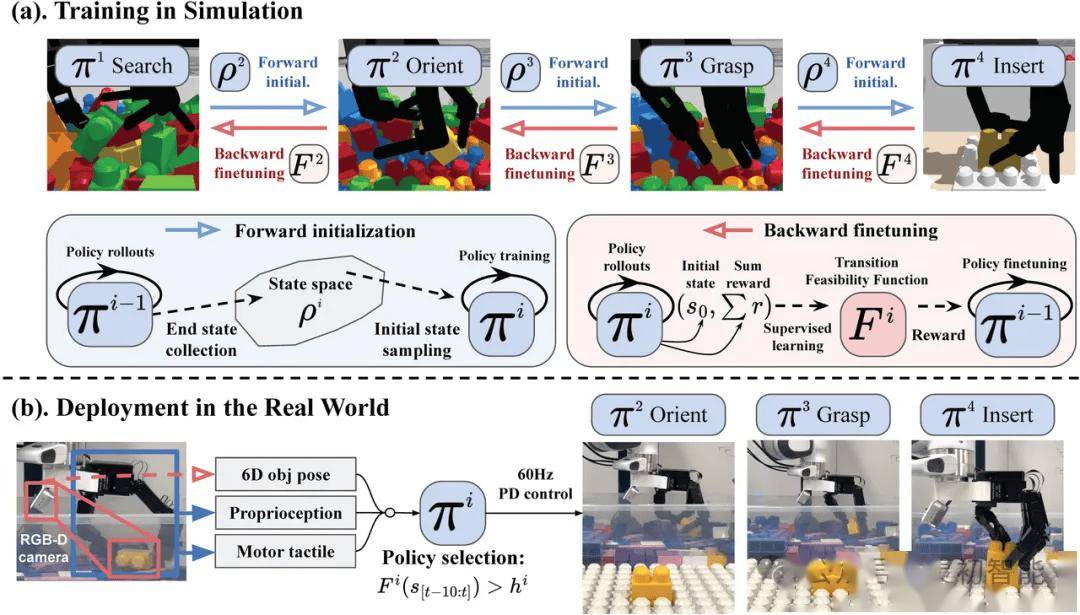
Psi R0的出色表現也離不開其背后的算法和數據處理技術的支持。靈初智能在算法優化和數據處理方面投入了大量的研發資源,確保了Psi R0能夠在各種復雜環境中穩定工作,并展現出卓越的性能。






















