近日,阿里巴巴旗下的通義千問Qwen團隊推出了一個名為CodeElo的基準測試,該測試旨在通過Elo評級系統(tǒng),對比大語言模型(LLM)與人類程序員的編程能力。
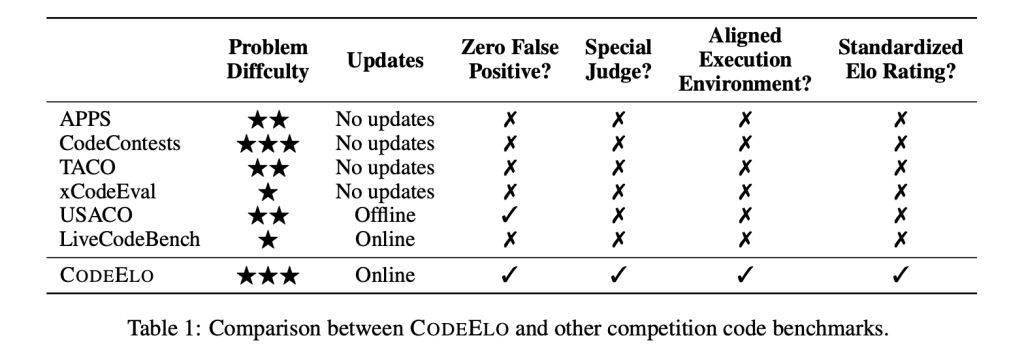
在AI應用場景中,大語言模型的一個關(guān)鍵應用是代碼生成與補全。然而,在評估LLM編程能力的真實性方面,業(yè)界面臨著諸多挑戰(zhàn)。現(xiàn)有的基準測試,如LiveCodeBench和USACO,都存在明顯的局限性,如缺乏健壯的私有測試用例、不支持專門的判斷系統(tǒng),以及執(zhí)行環(huán)境不一致等問題。
CodeElo基準測試的核心優(yōu)勢在于其全面性、穩(wěn)健性和標準化。在題目選擇上,CodeElo涵蓋了廣泛的比賽分區(qū)、難度級別和算法標簽,為LLM提供了全面的評估。在評估方法上,CodeElo利用CodeForces平臺的特殊評估機制,確保了對代碼準確性的判斷,避免了誤報等問題,并支持需要特殊評判機制的題目。在評級計算上,CodeElo采用Elo評級系統(tǒng),根據(jù)問題的難度和解決方案的正確性對LLM進行評分,并對錯誤進行懲罰,從而激勵高質(zhì)量的解決方案。
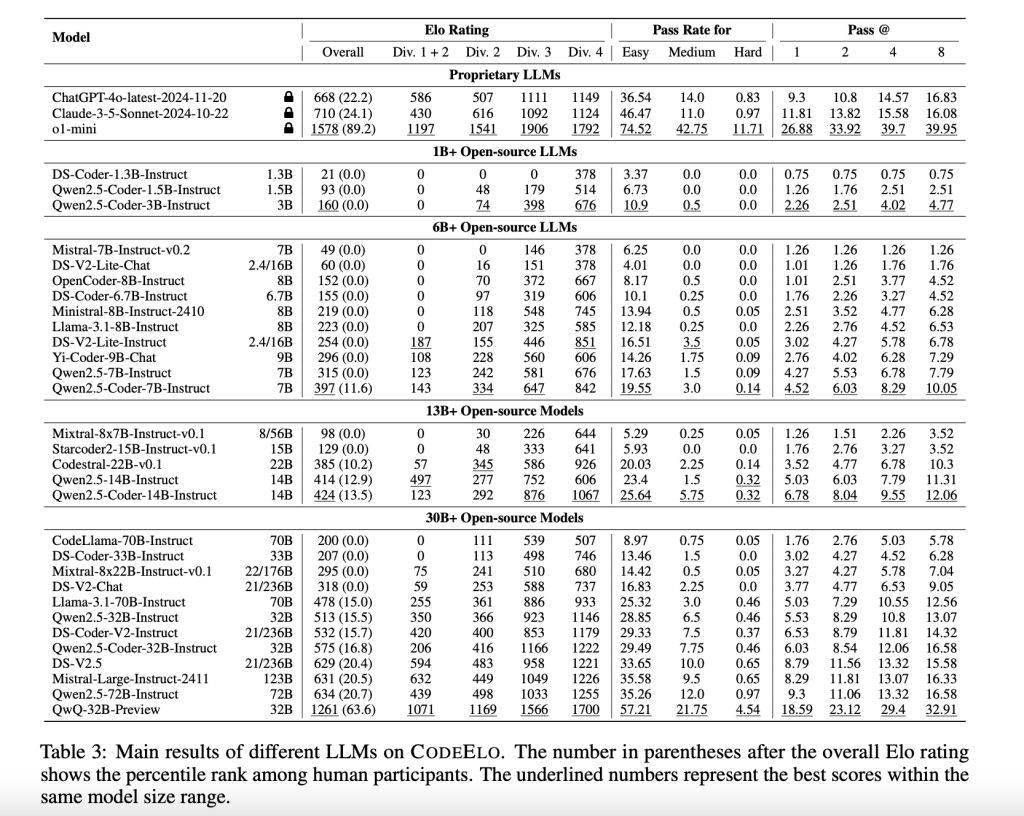
在對30個開源LLM和3個專有LLM進行測試后,結(jié)果顯示OpenAI的o1-mini模型表現(xiàn)最為出色,其Elo評分達到了1578,超過了90%的人類參與者。在開源模型中,QwQ-32B-Preview以1261分的成績位居榜首。然而,這些模型在解決簡單問題時仍然表現(xiàn)出一定的困難,通常排名在人類參與者的后20%左右。分析發(fā)現(xiàn),這些模型在數(shù)學和實現(xiàn)等類別上表現(xiàn)出色,但在動態(tài)規(guī)劃和樹形算法方面存在明顯的不足。
測試還發(fā)現(xiàn),當使用C++進行編碼時,LLM的表現(xiàn)更為出色,這與競技程序員的偏好一致。這些結(jié)果不僅揭示了LLM在編程能力方面的優(yōu)勢,也指出了其需要改進的領域。通過CodeElo基準測試,我們可以更加清晰地了解LLM在編程競賽中的表現(xiàn),并為未來的研究和開發(fā)提供有益的參考。
隨著技術(shù)的不斷發(fā)展,LLM在編程領域的應用將會越來越廣泛。CodeElo基準測試的推出,為評估LLM的編程能力提供了一個新的視角和工具。未來,我們可以期待更多類似的基準測試出現(xiàn),以推動LLM在編程領域的不斷進步和發(fā)展。






















