在農歷新年之際,當千家萬戶沉浸于節日的喜慶之時,科技界的競爭卻未曾停歇。一家來自杭州的新興企業DeepSeek,以其創新的技術和開源的姿態,在AI大模型領域掀起了一股新的熱潮。
DeepSeek近期發布的DeepSeek-V3模型,在多項評測中超越了Qwen2.5-72B和Llama-3.1-405B等開源模型,性能上與閉源模型GPT-4o和Claude-3.5-Sonnet不相上下。這一成就迅速吸引了業內人士的廣泛關注。而隨后發布的DeepSeek-R1推理模型,更是在性能上實現了對OpenAI-o1正式版的對標,同時公開了訓練技術并開源了模型權重。
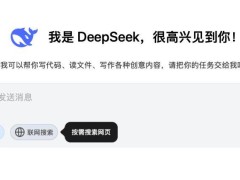
DeepSeek-R1不僅性能卓越,更重要的是,它為用戶提供了免費使用的機會。這一舉措無疑降低了AI技術的門檻,使得更多用戶能夠體驗到AI大模型的魅力。同時,DeepSeek-R1還支持聯網搜索信息,增加了使用的靈活性,使得用戶能夠更便捷地獲取信息并應用于實際工作中。
然而,DeepSeek的爆火也帶來了不小的壓力。隨著大量用戶的涌入,DeepSeek承受了巨大的訪問量和惡意攻擊。盡管如此,DeepSeek團隊依然堅守初心,不斷優化技術和服務,為用戶提供更好的體驗。

DeepSeek的成功,得益于其兩大核心技術:MoE混合專家模型和RL強化學習。MoE架構將復雜問題分解成多個更小、更易于管理的子問題,由不同的專家網絡分別處理,從而大大降低了推理成本。而RL強化學習則完全依賴環境反饋來優化模型行為,使得模型在訓練中自主發展出自我驗證、反思推理等復雜行為,達到ChatGPT o1級別的能力。
除了技術上的創新,DeepSeek還注重用戶體驗。DeepSeek-R1直接將思考過程顯示給用戶,讓用戶能夠直觀感受到大模型技術的實力。這一舉措不僅提升了用戶體驗,也增強了用戶對AI技術的信任感和依賴度。

DeepSeek還開源了全新的視覺多模態模型Janus-Pro-7B。這一模型通過將視覺編碼過程拆分為多個獨立的路徑,解決了以往框架中的局限性,提升了框架的靈活性。Janus-Pro在Geneval和DPG-Bench基準測試中擊敗了Stable Diffusion和OpenAI的DALL-E 3,成為下一代統一多模態模型的有力競爭者。

DeepSeek的崛起,也引起了其他AI大模型領域企業的關注。在DeepSeek發布DeepSeek-V3后不久,阿里通義團隊也帶來了他們的Qwen2.5-Max模型。這一模型使用超過20萬億token的預訓練數據及精心設計的后訓練方案進行訓練,性能表現與DeepSeek V3、GPT-4o和Claude-3.5-Sonnet等業界領先模型相當。

DeepSeek的成功不僅為AI大模型領域帶來了新的思路和技術創新,也推動了整個行業的發展。隨著越來越多的企業加入這一領域,AI技術的門檻將不斷降低,更多用戶將能夠體驗到AI技術的便利和魅力。同時,這也將促進AI技術在更多領域的應用和創新,為人類社會帶來更多的福祉和進步。