近期,OpenAI的研究團隊宣布了一項名為“深思熟慮的對齊”的創新技術,旨在提升人工智能模型的安全性,特別是在大型語言模型(LLMs)領域。這項技術已經在o系列模型中得到了成功應用,并顯示出顯著的成效。
面對確保大型語言模型遵循道德和安全標準的挑戰,現有的對齊技術,如監督微調(SFT)和基于人類反饋的強化學習(RLHF),雖有其優勢,但也存在明顯的局限。這些技術有時會被惡意提示所操縱,導致生成有害內容、拒絕合理請求或在面對陌生情境時表現不佳。這些問題的根源在于,模型往往是從數據中間接推斷安全標準,而非直接學習并理解這些標準。
為了解決這個問題,“深思熟慮的對齊”方法應運而生。它直接教授模型安全規范,并訓練模型在生成響應之前,先對這些規范進行推理,將安全原則內化為模型的一部分。這種方法不僅增強了模型的安全性,還提高了其在復雜或對抗性情境下的應對能力。
該技術的實施分為兩個階段。在第一階段,通過監督微調(SFT),模型學會了參考并推理安全規范,這一過程利用了從基礎模型生成的數據集。第二階段則引入了強化學習(RL),使用獎勵模型根據安全基準評估模型的性能,進一步優化其推理能力。值得注意的是,“深思熟慮的對齊”方法減少了對人工標注數據的依賴,而是利用模型生成的數據和思維鏈(CoT)推理,從而降低了安全訓練的資源成本。
OpenAI的o1模型已經部署了這項技術,并在實際測試中取得了令人矚目的成績。在抵抗越獄提示方面,o1模型在StrongREJECT基準測試中的得分高達0.88,遠超過GPT-4o的0.37分。同時,這項技術還有效減少了誤拒現象,在XSTest數據集的良性提示中,o1模型的準確率達到了93%。
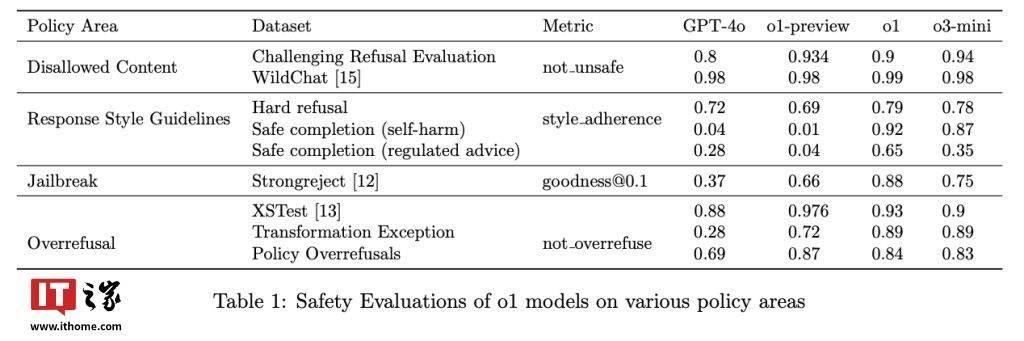
“深思熟慮的對齊”方法通過訓練模型明確推理安全策略,為復雜的倫理挑戰提供了切實可行的解決方案。這種方法不僅提高了模型的安全性,還增強了其可解釋性和可擴展性,為人工智能技術的未來發展開辟了新的道路。
























