近期,非營利組織“人工智能安全中心”(CAIS)攜手數據標注與AI開發服務商Scale AI,共同推出了一項名為“人類終極考試”的基準測試。該測試旨在全面評估前沿AI系統的綜合能力,其難度之高,引起了業界的廣泛關注。
這一基準測試的內容豐富多樣,涵蓋了數學、人文學科、自然科學等多個領域的問題。為了確保測試的權威性和深度,問題由來自50個國家/地區的500多個機構的近1000名學科專家撰稿人提出。這些專家包括教授、研究人員和研究生學位持有者,他們的專業知識為測試提供了堅實的基礎。

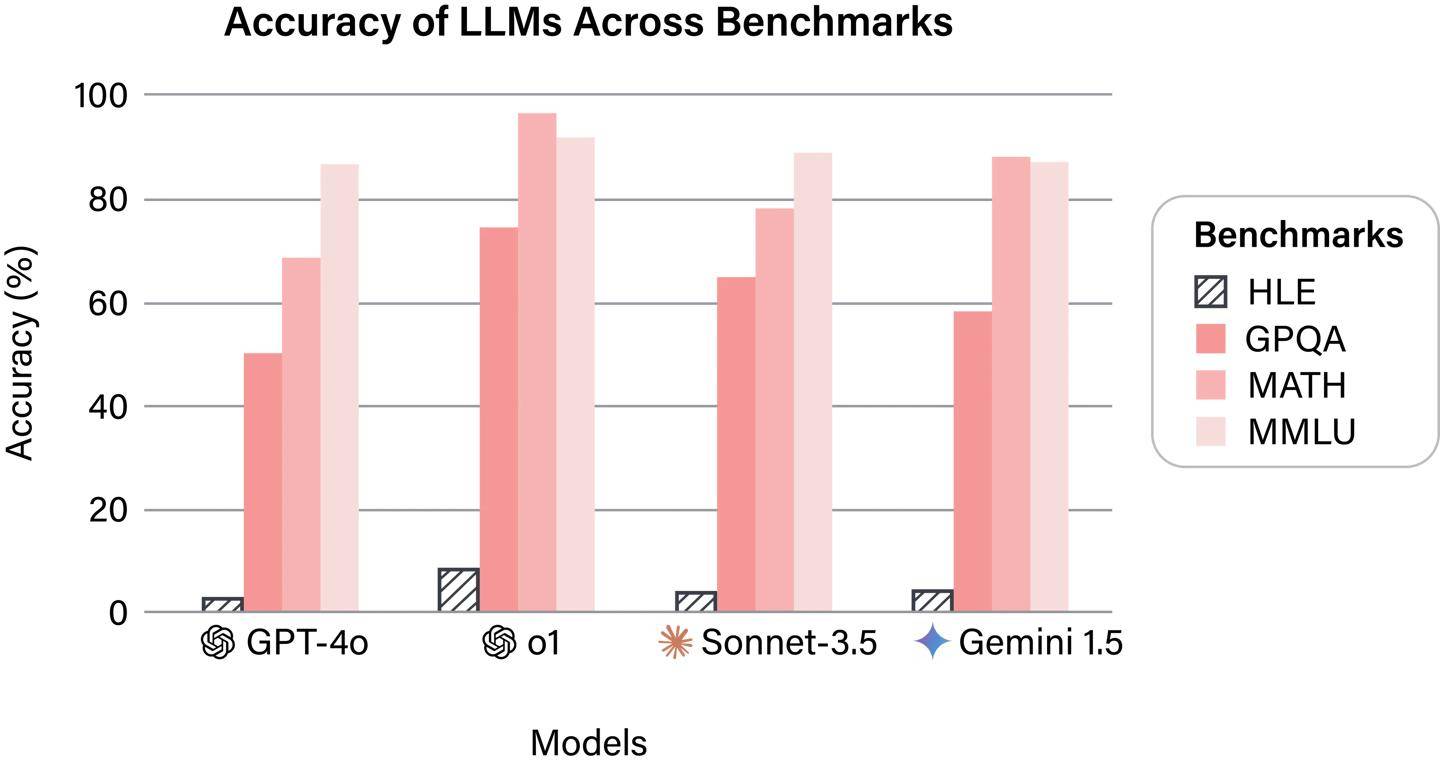
測試題目的設計也別具匠心,不僅包含了傳統的文字題目,還結合了圖表和圖像等復雜題型。這種多模態的信息呈現方式,旨在全面考察AI系統在跨學科知識和多模態信息處理方面的能力。這樣的測試設計,無疑對AI系統提出了更高的挑戰。
在初步的研究結果中,所有公開可用的旗艦AI系統在這一基準測試中的表現均不盡如人意。它們的回答準確率均未超過10%,這一結果揭示了當前AI技術在應對復雜、綜合性問題時的明顯短板。盡管AI技術在特定領域已經取得了顯著的進展,但在面對跨學科、多模態的綜合性問題時,仍然顯得力不從心。
除了揭示AI技術的短板外,“人類終極考試”還為研究人員提供了一個寶貴的平臺。CAIS和Scale AI計劃將這一基準測試向研究社區開放,以便研究人員能夠深入挖掘AI系統之間的差異,并評估新開發的AI模型。這將有助于推動AI技術的進一步發展,提高AI系統的綜合能力。
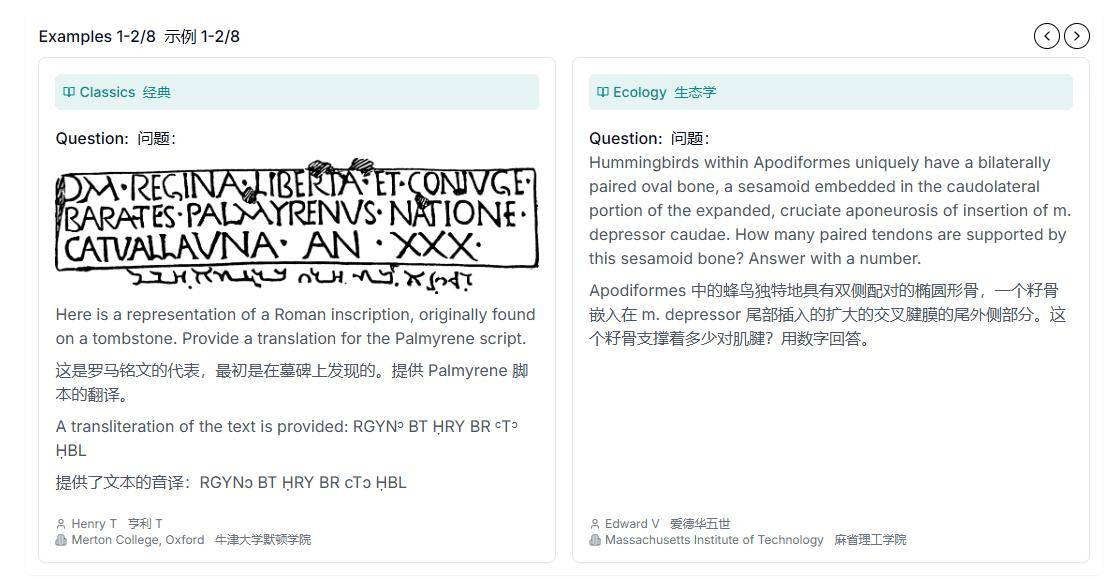
該基準測試還展示了跨學科合作的重要性。來自不同領域的專家共同參與了測試題目的設計和評估工作,他們的專業知識和經驗為測試的準確性和深度提供了有力保障。這種跨學科的合作方式,不僅有助于推動AI技術的發展,還能促進不同學科之間的交流和融合。