站在門口看一眼,AI 就能腦補出房間里面長什么樣:

是不是有線上 VR 看房那味兒了?不只是室內效果,來個遠景長鏡頭航拍也是 so easy:

而且渲染出的圖像通通都是高保真效果,仿佛是用真相機拍出來的一樣。最近一段時間,用 2D 圖片合成 3D 場景的研究火了一波又一波。但是過去的許多研究,合成場景往往都局限在一個范圍比較小的空間里。比如此前大火的 NeRF,效果就是圍繞畫面主體展開。

這一次的新進展,則是將視角進一步延伸,更側重讓 AI 預測出遠距離的畫面。
比如給出一個房間門口,它就能合成穿過門、走過走廊后的場景了。

目前,該研究的相關論文已被 CVPR2022 接收。
輸入單張畫面和相機軌跡
讓 AI 根據一個畫面,就推測出后面的內容,這個感覺是不是和讓 AI 寫文章有點類似?實際上,研究人員這次用到的正是 NLP 領域常用的 Transformer。他們利用自回歸 Transformer 的方法,通過輸入單個場景圖像和攝像機運動軌跡,讓生成的每幀畫面與運動軌跡位置一一對應,從而合成出一個遠距離的長鏡頭效果。
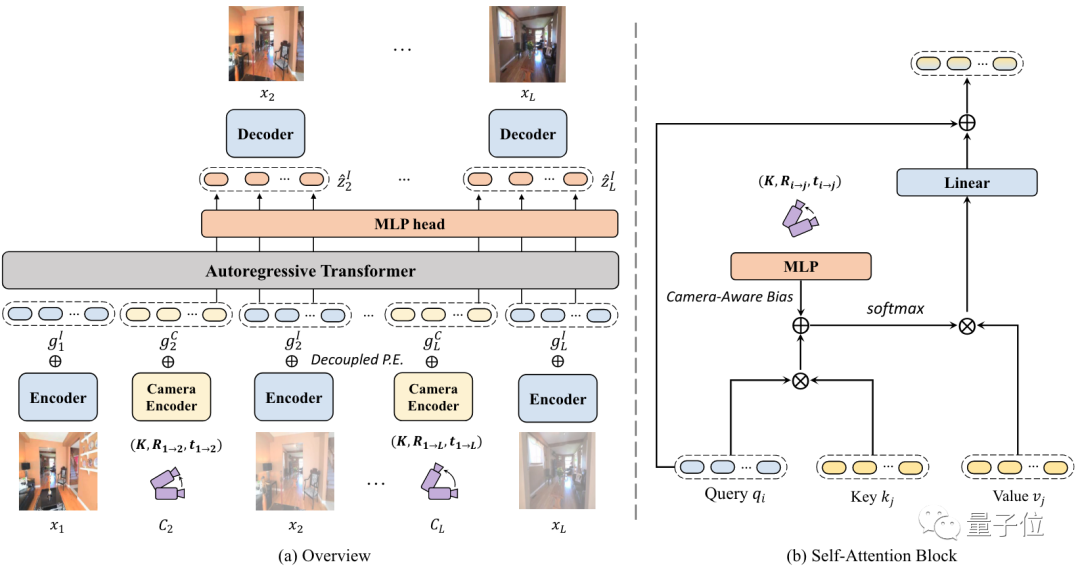
整個過程可以分為兩個階段。
第一階段先預訓練了一個 VQ-GAN,可以把輸入圖像映射到 token 上。VQ-GAN 是一個基于 Transformer 的圖像生成模型,其最大特點就是生成的圖像非常高清。在這部分,編碼器會將圖像編碼為離散表示,解碼器將表示映射為高保真輸出。
第二階段,在將圖像處理成 token 后,研究人員用了類似 GPT 的架構來做自回歸。具體訓練過程中,要將輸入圖像和起始相機軌跡位置編碼為特定模態的 token,同時添加一個解耦的位置輸入 P.E.。然后,token 被喂給自回歸 Transformer 來預測圖像。模型從輸入的單個圖像開始推理,并通過預測前后幀來不斷增加輸入。
研究人員發現,并非每個軌跡時刻生成的幀都同樣重要。因此,他們還利用了一個局部性約束來引導模型更專注于關鍵幀的輸出。這個局部性約束是通過攝像機軌跡來引入的。基于兩幀畫面所對應的攝像機軌跡位置,研究人員可以定位重疊幀,并能確定下一幀在哪。
為了結合以上內容,他們利用 MLP 計算了一個“相機感知偏差”。這種方法會使得在優化時更加容易,而且對保證生成畫面的一致性上,起到了至關重要的作用。
實驗結果
本項研究在 RealEstate10K、Matterport3D 數據集上進行實驗。結果顯示,相較于不規定相機軌跡的模型,該方法生成圖像的質量更好。

與離散相機軌跡的方法相比,該方法的效果也明顯更好。

作者還對模型的注意力情況進行了可視化分析。結果顯示,運動軌跡位置附近貢獻的注意力更多。

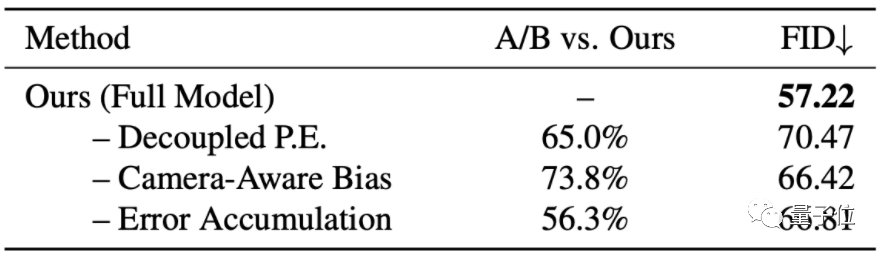
在消融實驗上,結果顯示該方法在 Matterport3D 數據集上,相機感知偏差和解耦位置的嵌入,都對提高圖像質量和幀與幀之間的一致性有所幫助。
兩位作者均是華人
Xuanchi Ren 為香港科技大學本科生。

他曾在微軟亞研院實習過,2021 年暑期與 Xiaolong Wang 教授有過合作。
Xiaolong Wang 是加州大學圣地亞哥分校助理教授。

他博士畢業于卡內基梅隆大學機器人專業。研究興趣有計算機視覺、機器學習和機器人等。特別自我監督學習、視頻理解、常識推理、強化學習和機器人技術等領域。
論文地址:
https://xrenaa.github.io/look-outside-room/